 an impressive bunch of women, watch out world! 😉
an impressive bunch of women, watch out world! 😉 
was one of the WIK meetup reviews and I can’t argue with that. The heavens have certainly tested our resolve, but the Women in Kaggle refuse to be defeated! They have proven their dedication again and never cease to amaze me! Last month they defied tempestuous weather conditions and this week they crossed a sweltering capital in droves (well…) on the hottest day of the year so far and in rush hour – now that’s intrepid. And that was before the action even started…
One new member joined us on Wednesday on the recommendation of a fellow passenger on a flight to New Zealand (how freaky is that?!) – demonstrating that there truly are no bounds the Women in Kaggle won’t surpass to spread the word! We were also delighted to receive a personal endorsement from Ben Hamner, the CTO of Kaggle, when he and the company lent us their support on Twitter:
Excited to see the @WomenInKaggle London meetup and blog!
Kim kicked off Wednesday evening with a thought provoking insight into her entry to a competition supported by MI5 and MI6 and “designed to bring the brightest minds in data science together to solve real world problems”. As we ladies relaxed over a glass of wine in the welcoming and super comfortable Thoughtworks Soho office space, Kim talked us through her approach and answered pertinent questions posed by a shrewd audience…

Riveting stuff!

Demoing documents to data
We followed up with animated discussions on the talk, on data science in general, on the structure and progress of the group and on other, more colourful topics over pizza kindly supplied by H2O, and more wine generously supplied by Thoughtworks. And a wonderful time was had by all…
We generated loads of ideas amongst us including how to continue exploring language agnostic problem solving skills using Kaggle’s House Prices competition as a framework in which to learn interactively…building monthly on shared knowledge and growing a codebase. Georgie and I are meeting next week to setup a WIK github repo as lots of members are keen to contribute!
We’ll probably follow two strands – taking the House Prices and following it through to a conclusion and at the same time starting another very exciting project that we will unveil at the next meetup, so do make sure you book your space in good time!
For those who couldn’t make it this week, here’s a summary of Kim’s presentation and a big shout out to Redpixie for letting us reproduce Kim’s original blogpost here! I’ll be posting her slides on the slack channel – email me if you need access and the code is available here.
The challenge
The first challenge involved classifying types of vehicles from aerial photos. The second, and my chosen subject centered on classifying crisis documents based on their topics.
Specific details of ‘Growing Instability: Classifying Crisis Reports’ can be found here.
We were given a dataset of news articles and documents that relate to a humanitarian crisis.
The intention was to use this sample to build a model that can determine the topics for future documents so that they can be classified and used to detect signs of growing instability.
The main challenges to this problem were:
- Dealing with multi-label classification of complex and sometimes ambiguous articles
- Using historical documents to predict themes of future documents
- Working with text data, or NLP (Natural Language Processing), which is one of the most challenging and interesting fields of Artificial Intelligence.
Preparing the datasets
My solution was built in Python and using the packages spaCy for natural language processing and scikit-learn for machine learning.
The training collection contained approximately 1.6 million documents and each article could be labelled with one or more topics, e.g. article X could be about ‘war’, ‘Middle East’ and ‘politics’.
The collection also contained articles and topics that were not of interest e.g. ‘sports’ and ‘lifestyle’. In total, 160 topics were of interest to the challenge.
Processing 1.6 million documents
The first step in any analysis is to understand our data, but the size of the dataset presented a challenge.
With more than 1.6 million articles to process, we were dealing with data volumes far larger than what could be efficiently ingested on a single laptop.
One generally accepted approach is to try sample a representative subset of articles, which would be of a much more manageable size. For example, removing topics and articles from the dataset not relevant to the challenge. A quick histogram plot of the remaining articles revealed an unequal representation of the topics and 14 topics did not even contain any articles.
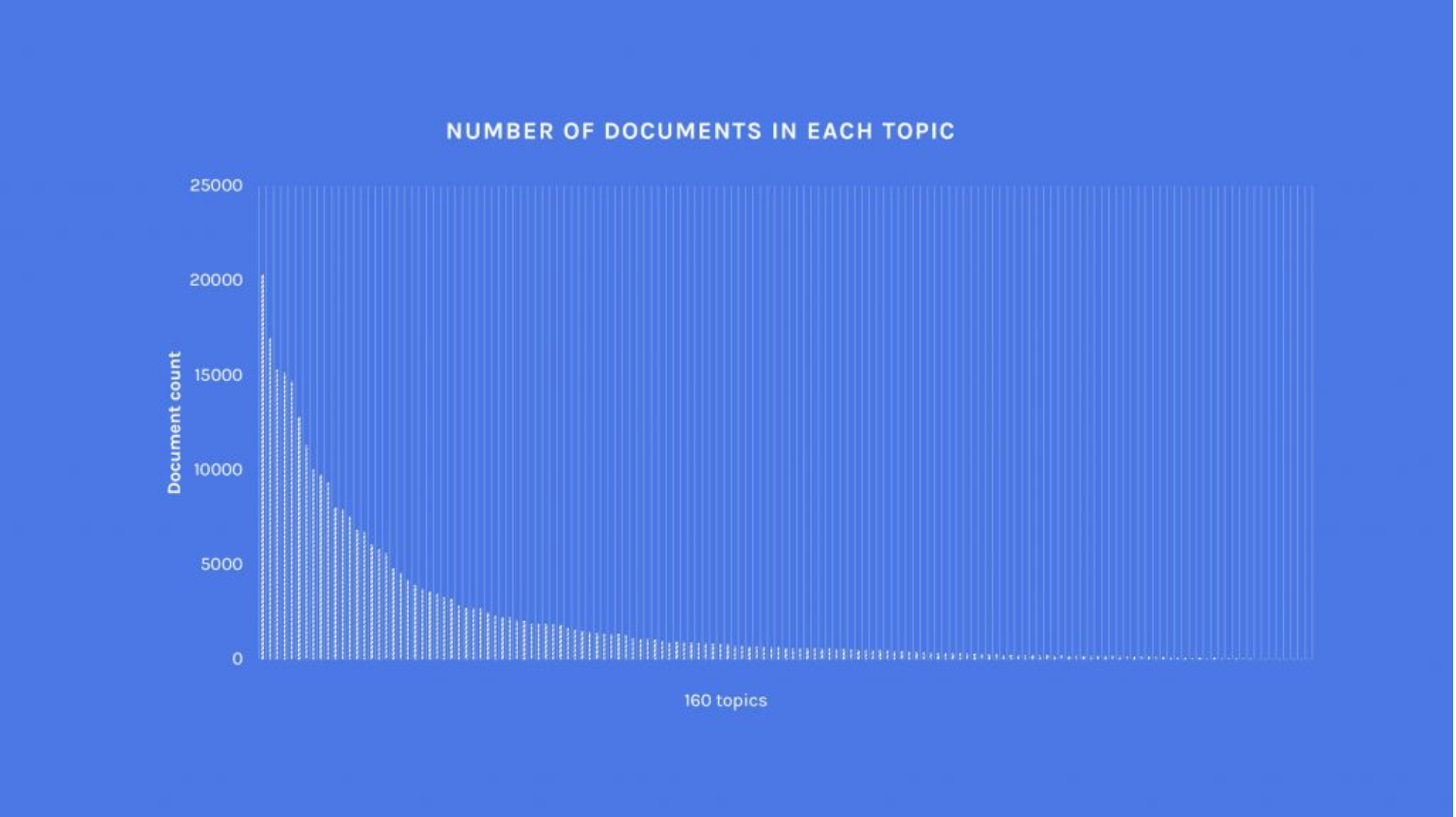
Training a model with too few documents for a given topic will typically generate noise and will not generalize well to future documents.
Additional data for topics with fewer than 200 documents were naively inferred from the text. E.g. searching for the label ‘activism’ within the text and label it if it is present. The NY Times API was used for additional documents for topics that could not be inferred from the documents.
Converting documents into data
The second step is turning articles into numbers so that we can build a statistical model.
This process is called feature extraction, and in our case, we are building word vectors.
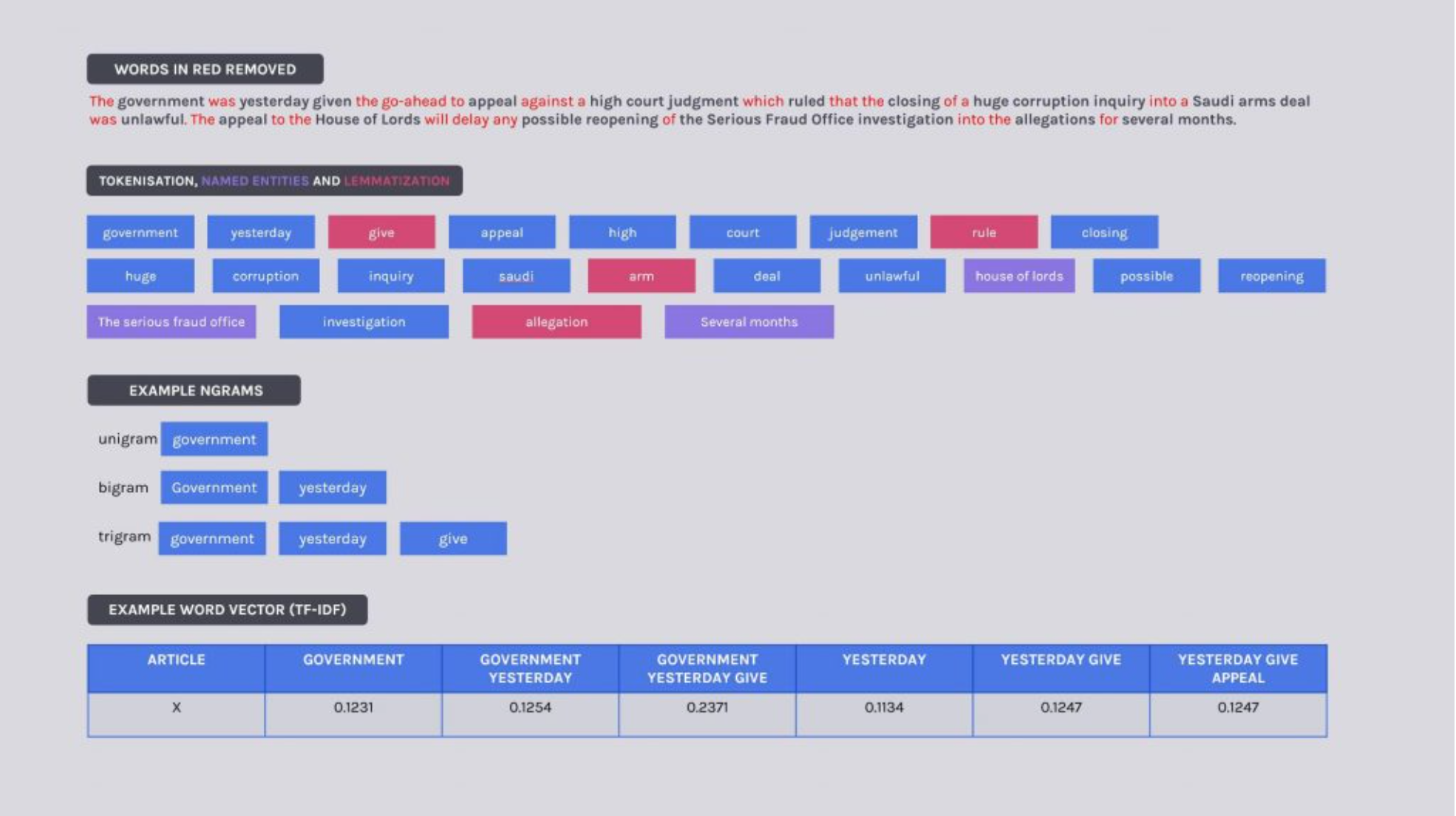
Classic NLP techniques such as tokenization, extraction of named entities and lemmatization of each article were performed. I also removed punctuation, stop words, white space, numbers, symbols, very common and uncommon words and types of part-of-speech tags from each article.
The idea is that by removing these from the articles we can focus on the important words instead.
I then applied a term frequency-inverse document frequency (tf-idf) weight to unigram, bigram and trigram sizes of words in the document. This weight is a measure of how important a word is to the document in the collection. The result is a high dimensional sparse matrix using the tf-idf scores per word as features.
Creating suitable models
The data is then partitioned into a training set to train the model and a test set to evaluate it. This also can be done k-folds time for further model evaluation.
The model I felt best suited for this type of data was Support Vector Machines (SVM), a supervised machine learning classification method. SVM can handle large datasets as in this case we had 10,000+ features. I evaluated the performance of other supervised learning methods, but they did not cope so well with the number of dimensions in the training data.
A linear SVM was used in combination with the OneVsRestClassifier function in the scikit-learn package. The OneVsRestClassifier can efficiently fit one label per classifier and outputs are easy to interpret.
The model was evaluated using the micro F1 score on the test set, which is an overall measure of a model’s accuracy but it considers both the precision and recall. A grid search algorithm was used to find the best parameters for the model that returned the highest F1 score.
I retrained the model on the entire dataset using the best parameters and ran it against the unseen test set provided.
The predicted results for each article in the test set contained a series of 0s and 1s for the 160 topics, where a 1 indicated presence of the topic.
This file was uploaded onto the competition’s platform where a score was automatically generated onto the public leaderboard for 30% of the data. A private leaderboard was not displayed until the end of the competition.
The results
Overall, I achieved a top 20 ranking out of 579 entries for my first data science competition.
I think with hindsight, I would look into other approaches to improve this score and overall ranking such as, investigating different feature vectors such as word embeddings.
What this challenge has shown me is that real world data is not always clean and structured and majority of the time is spent preparing the dataset (pre-processing), otherwise it is garbage in garbage out!
Thanks Kim!
And by chance I came across this relevant post the following day and thought it might be of interest too…
Keep Kaggling till the next time,
Founder of

1 thought on “Midsummer night’s dream…”